46.🌟Permutations
https://leetcode.com/problems/permutations/
1.Description(Medium)
Given a list of numbers, return all possible permutations.
Notice
You can assume that there is no duplicate numbers in the list.
Example
For nums =[1,2,3], the permutations are:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]2.Code
http://www.cnblogs.com/grandyang/p/4358848.html
http://www.jiuzhang.com/solutions/permutations/
视频讲解: https://www.bilibili.com/video/BV1P5411N7Xc
Permutation的解题方法和Combination几乎是相同的,唯一需要注意的是,Permutation需要加一个bool类型的数组来进行记录哪个元素访问了,哪个没有,这样才不会导致重复出现,并且不同于Combination的一点是,Permutation不需要排序.
解题思路: 遇到这种问题,很显然,第一个想法我们首先回去想到DFS,递归求解,对于数组中的每一个元素,找到以他为首节点的Permutations,这就要求在递归中,每次都要从数组的第一个元素开始遍历,这样,,就引入了另外一个问题,我们会对于同一元素访问多次,这就不是我们想要的答案了,所以我们引入了一个bool类型的数组,用来记录哪个元素被遍历了(通过下标找出对应).在对于每一个Permutation进行求解中,如果访问了这个元素,我们将它对应下表的bool数组中的值置为true,访问结束后,我们再置为false.
时间复杂度分析: 这道题同Combination,所以对于这道题的解答,时间复杂度同样是O(n!)
Note:Line20 不直接 result.add(path)是因为如果直接add(path), 后面修改path(add) 的时候,result里的path也会跟着改变。而result.add(new ArrayList(path)). result里的元素不会跟着path修改而而修改。因为递归一直传递的是一个List Object,这里如果不重新new一个新的对象,result里重续加入了同一个对象所以值是相同的。
简洁一点的:不用visited数组,利用list的contains函数
Version 3: https://labuladong.github.io/algo/4/29/105/
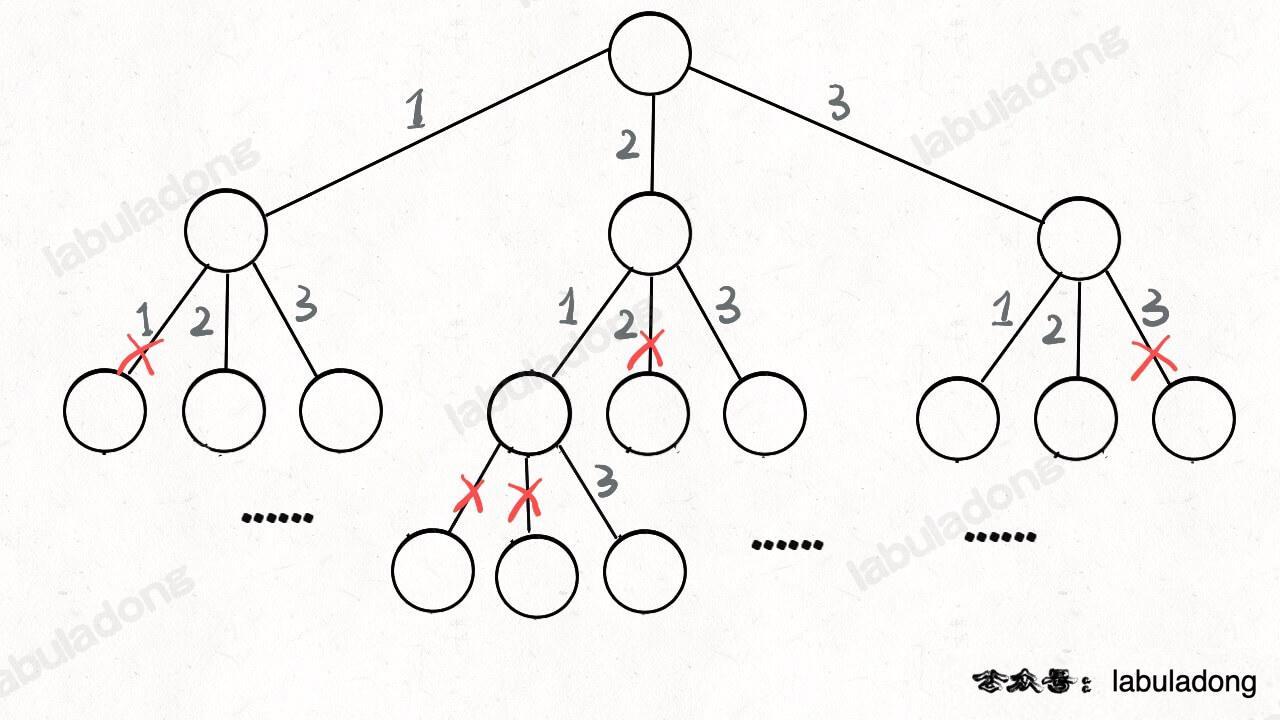
其实这就是回溯算法,我们高中无师自通就会用,或者有的同学直接画出如下这棵回溯树:
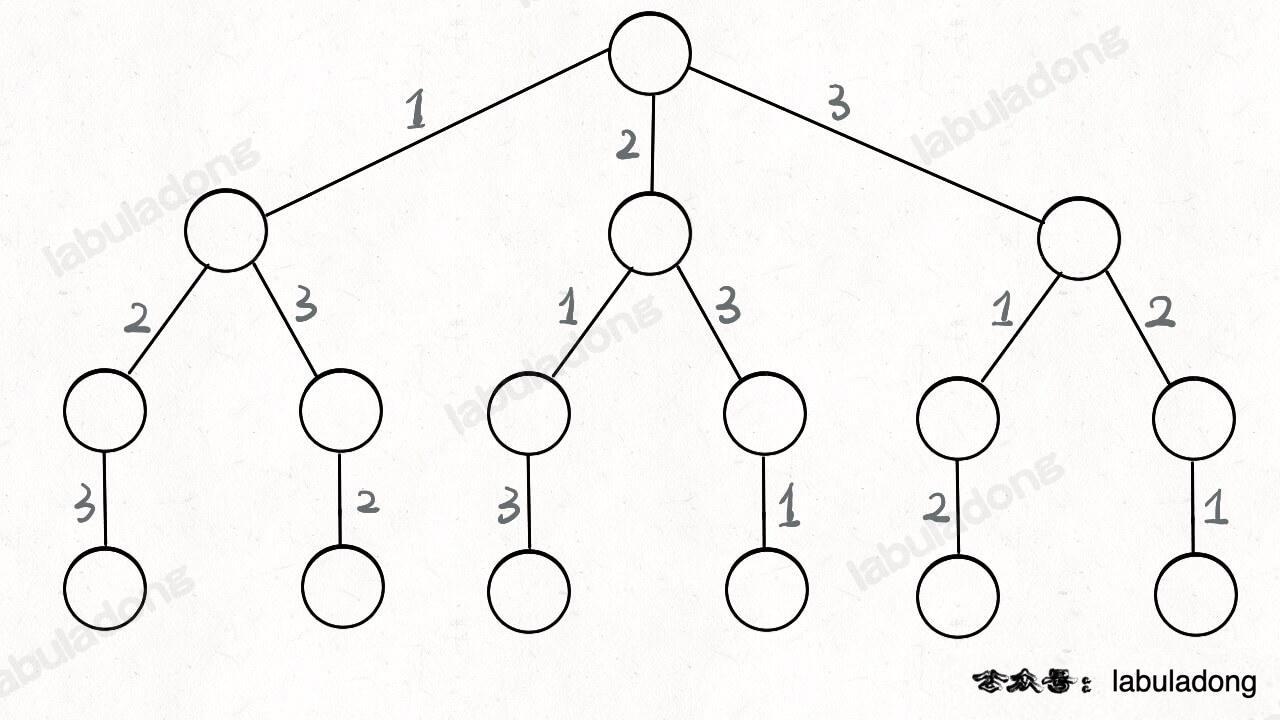
只要从根遍历这棵树,记录路径上的数字,其实就是所有的全排列。我们不妨把这棵树称为回溯算法的「决策树」。
为啥说这是决策树呢,因为你在每个节点上其实都在做决策。比如说你站在下图的红色节点上:
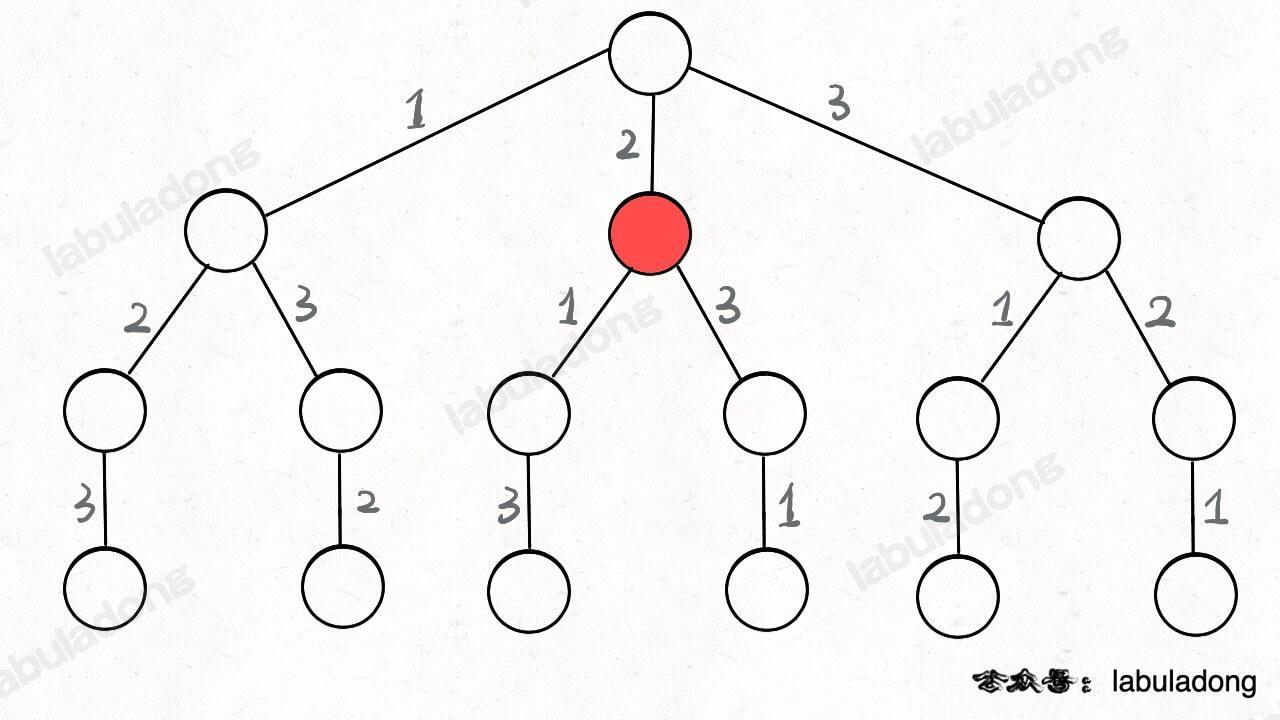
你现在就在做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。为啥只能在 1 和 3 之中选择呢?因为 2 这个树枝在你身后,这个选择你之前做过了,而全排列是不允许重复使用数字的。
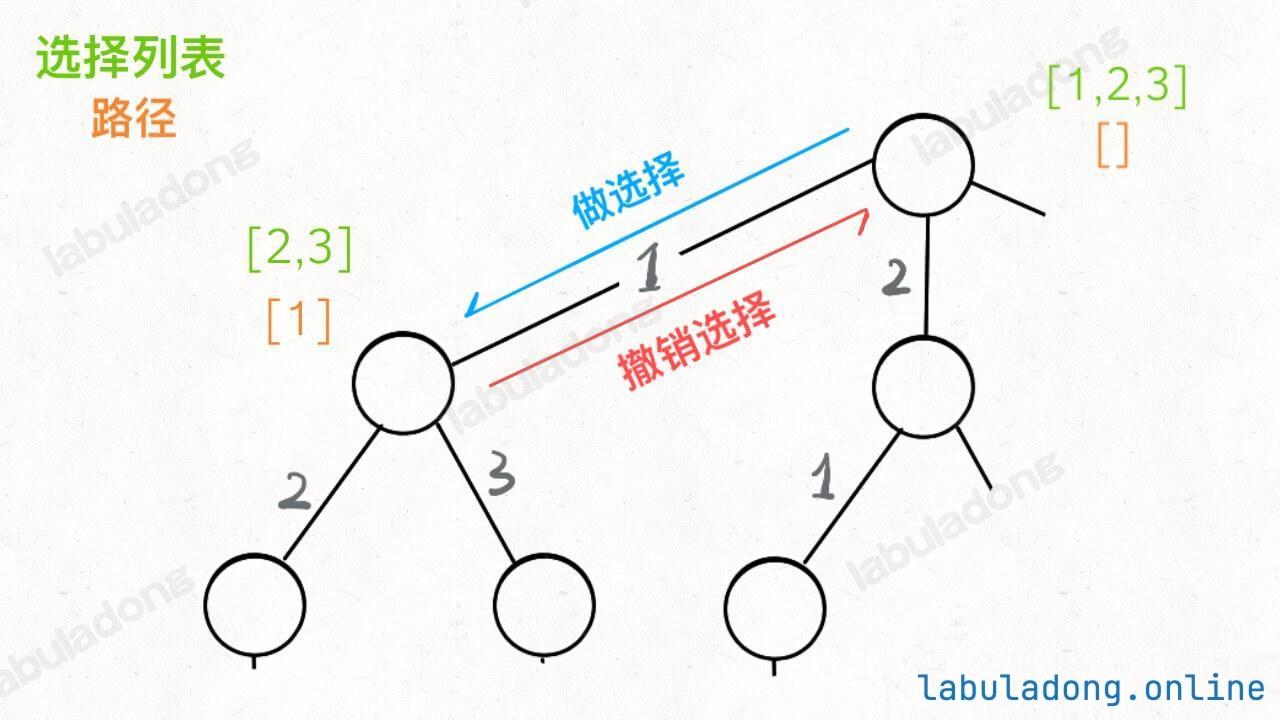
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
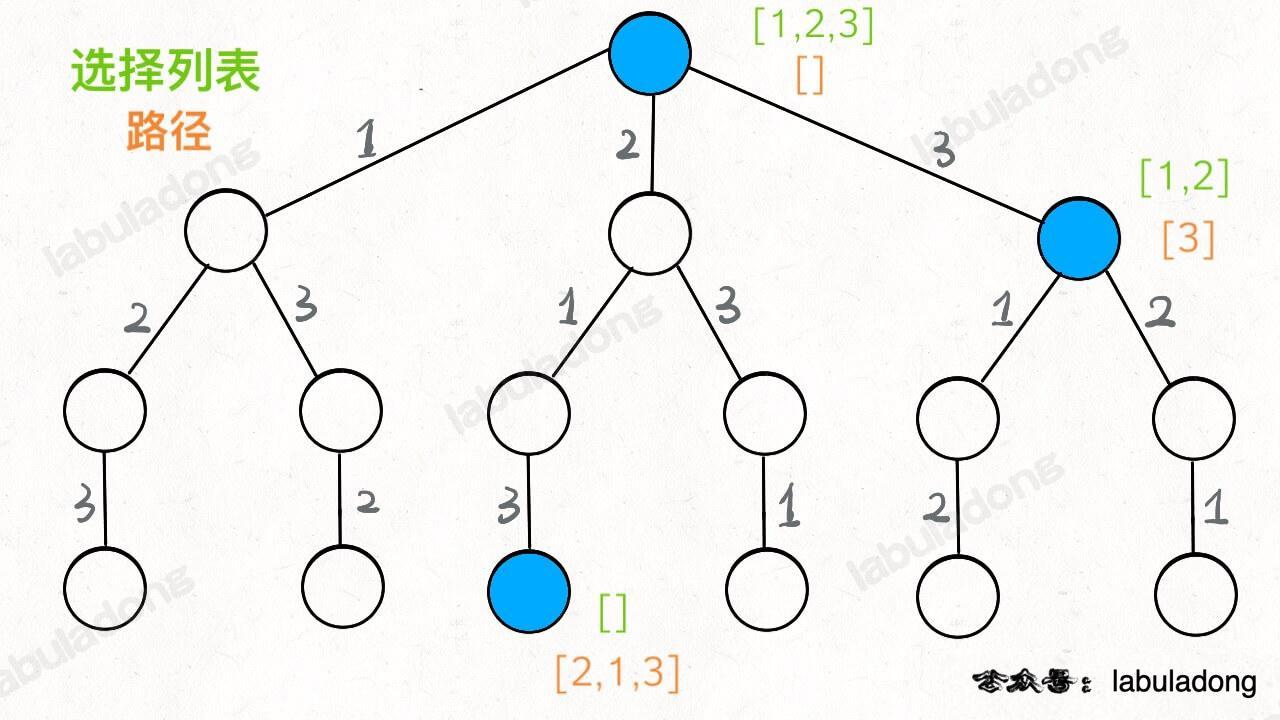
我们定义的 backtrack 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其「路径」就是一个全排列。
再进一步,如何遍历一棵树?这个应该不难吧。回忆一下之前 学习数据结构的框架思维 写过,各种搜索问题其实都是树的遍历问题,而多叉树的遍历框架就是这样:
而所谓的前序遍历和后序遍历,他们只是两个很有用的时间点,我给你画张图你就明白了:
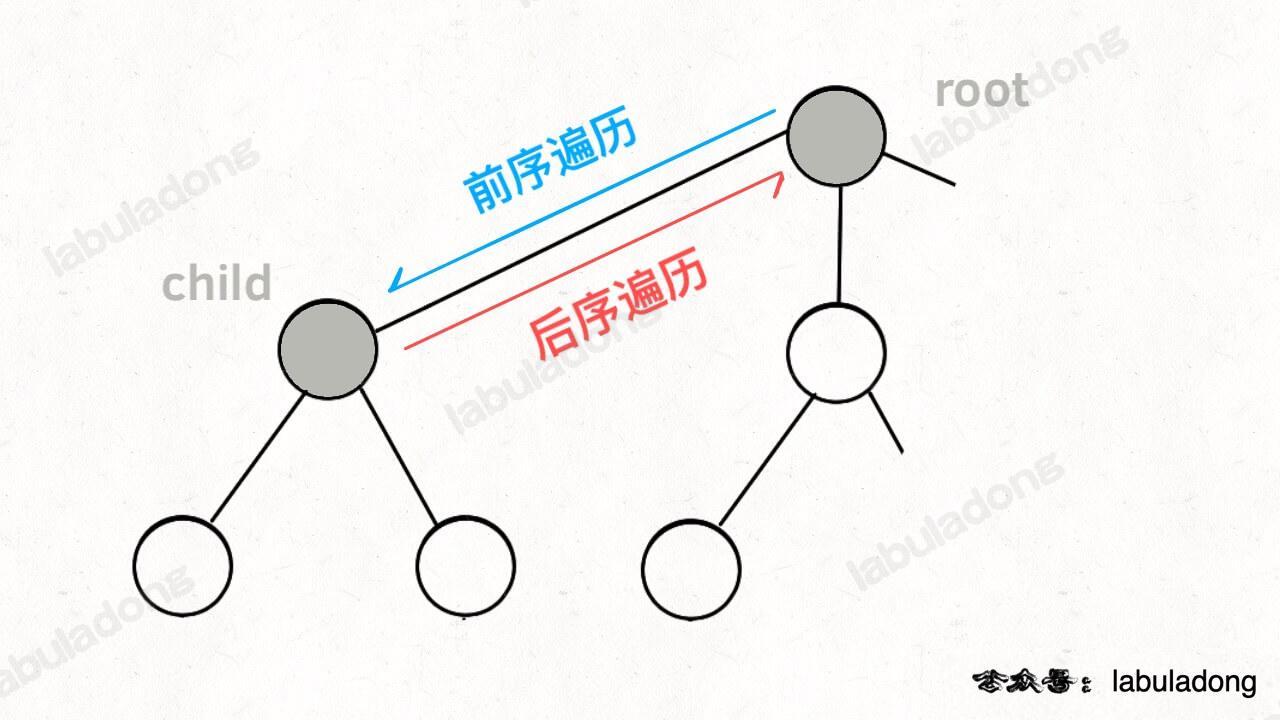
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
现在,你是否理解了回溯算法的这段核心框架?
我们只要在递归之前做出选择,在递归之后撤销刚才的选择,就能正确得到每个节点的选择列表和路径。
下面,直接看全排列代码:
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 contains 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高
Last updated