# Union-Find
Union-Find 算法解决的是图的**动态连通性问题**
#### 一、问题介绍
简单说,动态连通性其实可以抽象成给一幅图连线。比如下面这幅图,总共有 10 个节点,他们互不相连,分别用 0\~9 标记:
[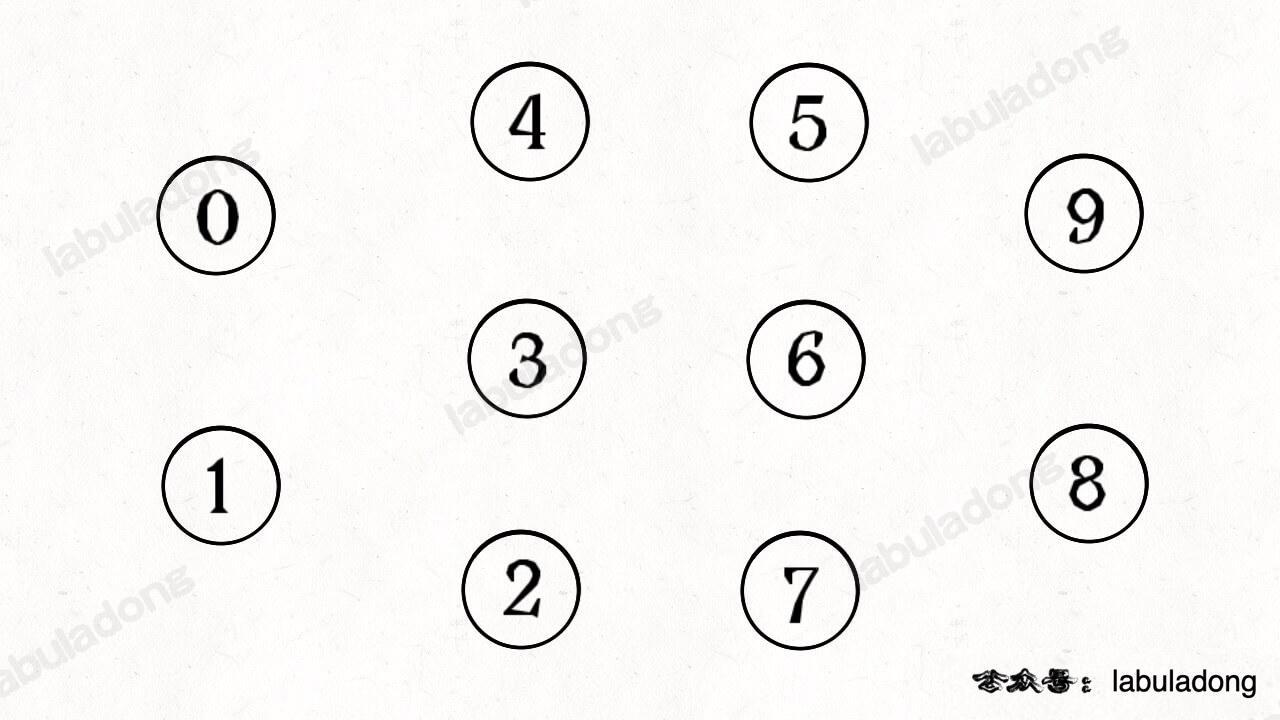](https://labuladong.github.io/algo/images/unionfind/1.jpg)
现在我们的 Union-Find 算法主要需要实现这两个 API:
```java
class UF {
/* 将 p 和 q 连接 */
public void union(int p, int q);
/* 判断 p 和 q 是否连通 */
public boolean connected(int p, int q);
/* 返回图中有多少个连通分量 */
public int count();
}
```
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点 `p` 和 `p` 是连通的。
2、对称性:如果节点 `p` 和 `q` 连通,那么 `q` 和 `p` 也连通。
3、传递性:如果节点 `p` 和 `q` 连通,`q` 和 `r` 连通,那么 `p` 和 `r` 也连通。
比如说之前那幅图,0~9 任意两个**不同**的点都不连通,调用 `connected` 都会返回 false,连通分量为 10 个。
如果现在调用 `union(0, 1)`,那么 0 和 1 被连通,连通分量降为 9 个。
再调用 `union(1, 2)`,这时 0,1,2 都被连通,调用 `connected(0, 2)` 也会返回 true,连通分量变为 8 个。
[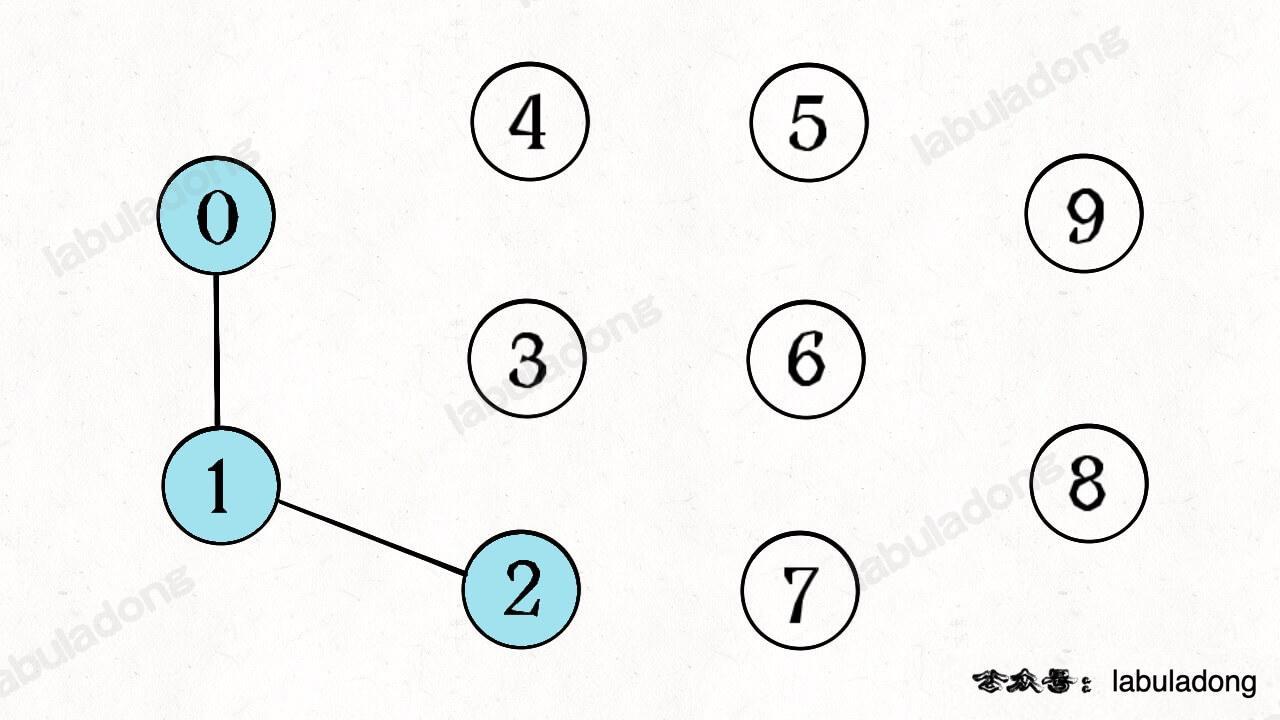](https://labuladong.github.io/algo/images/unionfind/2.jpg)
判断这种「等价关系」非常实用,比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。
这样,你应该大概明白什么是动态连通性了,Union-Find 算法的关键就在于 `union` 和 `connected` 函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
#### 二、基本思路
注意我刚才把「模型」和具体的「数据结构」分开说,这么做是有原因的。因为我们使用森林(若干棵树)来表示图的动态连通性,用数组来具体实现这个森林。
怎么用森林来表示连通性呢?我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。比如说刚才那幅 10 个节点的图,一开始的时候没有相互连通,就是这样:
[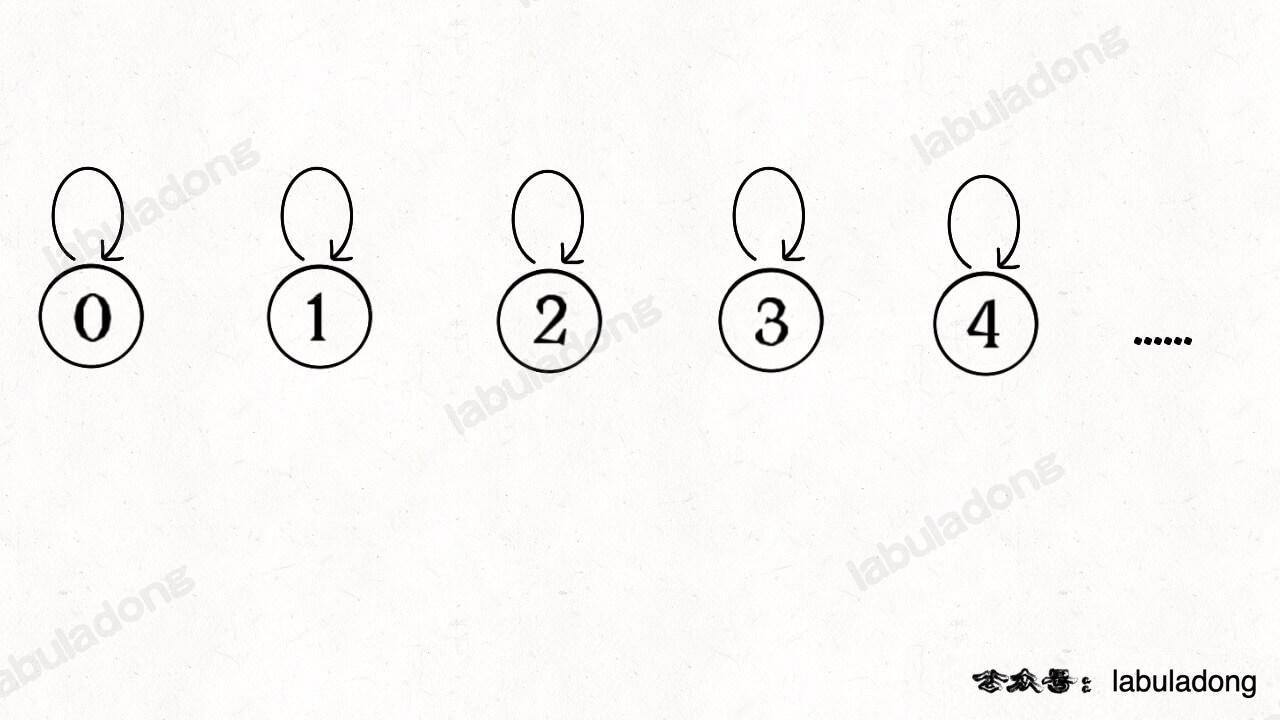](https://labuladong.github.io/algo/images/unionfind/3.jpg)
```java
class UF {
// 记录连通分量
private int count;
// 节点 x 的节点是 parent[x]
private int[] parent;
/* 构造函数,n 为图的节点总数 */
public UF(int n) {
// 一开始互不连通
this.count = n;
// 父节点指针初始指向自己
parent = new int[n];
for (int i = 0; i < n; i++)
parent[i] = i;
}
/* 其他函数 */
}
```
**如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上**:
[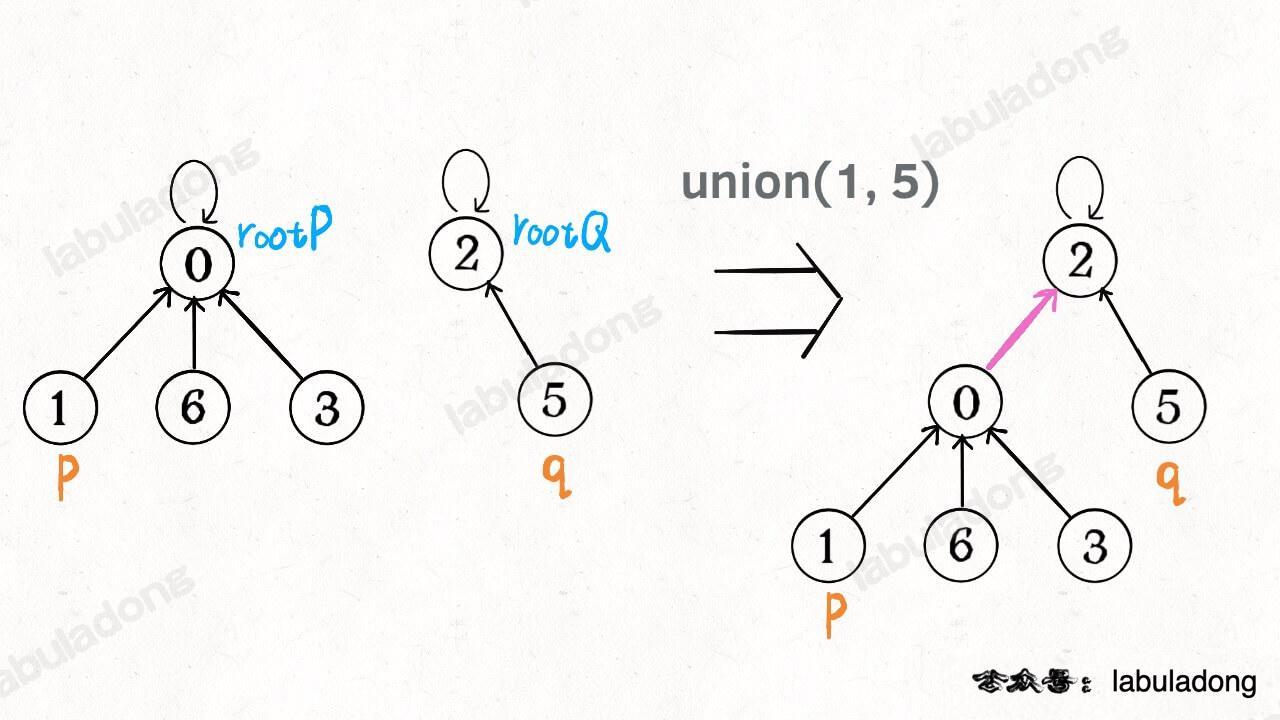](https://labuladong.github.io/algo/images/unionfind/4.jpg)
```java
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 将两棵树合并为一棵
parent[rootP] = rootQ;
// parent[rootQ] = rootP 也一样
count--; // 两个分量合二为一
}
/* 返回某个节点 x 的根节点 */
private int find(int x) {
// 根节点的 parent[x] == x
while (parent[x] != x)
x = parent[x];
return x;
}
/* 返回当前的连通分量个数 */
public int count() {
return count;
}
```
**这样,如果节点 `p` 和 `q` 连通的话,它们一定拥有相同的根节点**:
[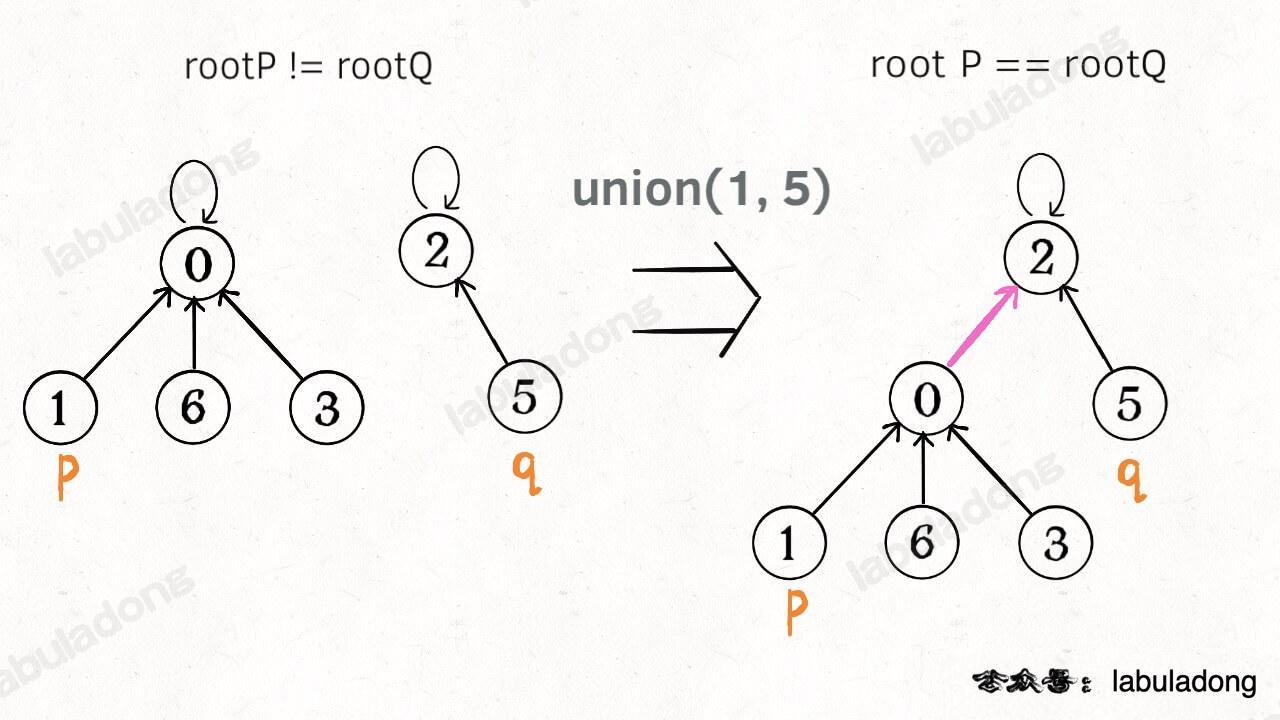](https://labuladong.github.io/algo/images/unionfind/5.jpg)
```java
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
```
至此,Union-Find 算法就基本完成了。是不是很神奇?竟然可以这样使用数组来模拟出一个森林,如此巧妙的解决这个比较复杂的问题!
那么这个算法的复杂度是多少呢?我们发现,主要 API `connected` 和 `union` 中的复杂度都是 `find` 函数造成的,所以说它们的复杂度和 `find` 一样。
`find` 主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是 `logN`,但这并不一定。`logN` 的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成 `N`。
[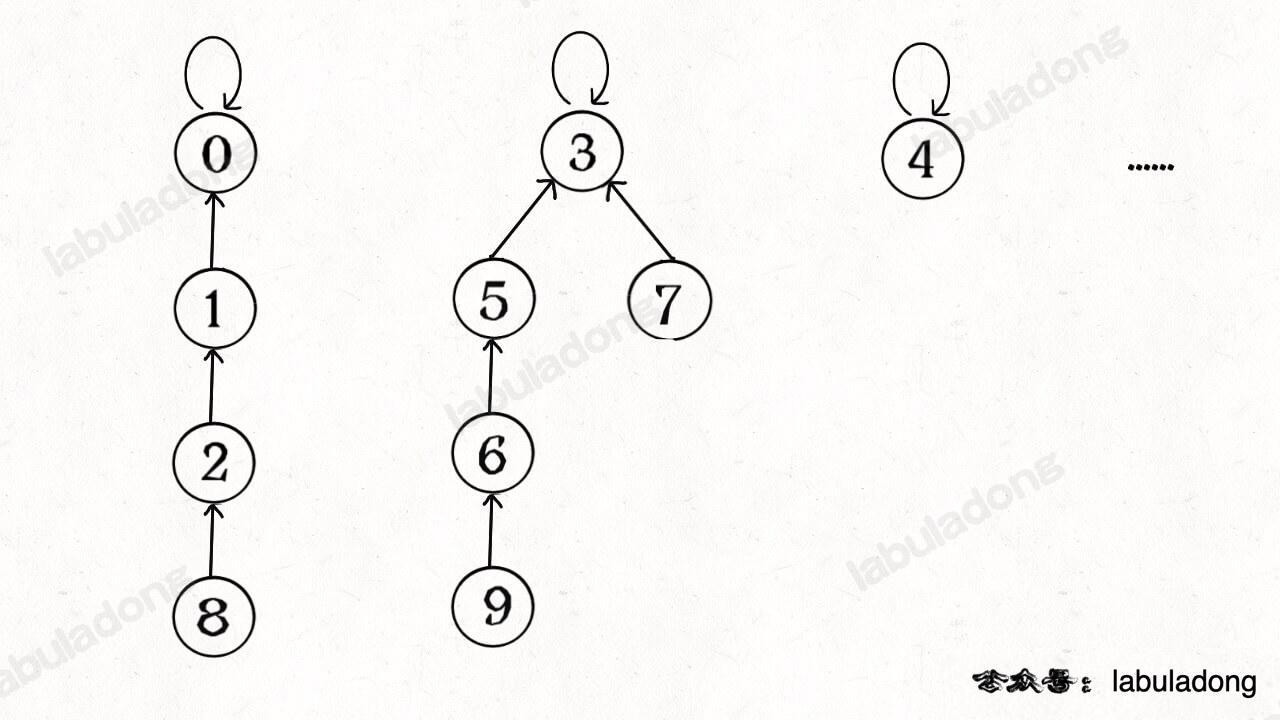](https://labuladong.github.io/algo/images/unionfind/6.jpg)
所以说上面这种解法,`find` , `union` , `connected` 的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于 `union` 和 `connected` 的调用非常频繁,每次调用需要线性时间完全不可忍受。
**问题的关键在于,如何想办法避免树的不平衡呢**?只需要略施小计即可。
#### 三、平衡性优化
我们要知道哪种情况下可能出现不平衡现象,关键在于 `union` 过程:
```java
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 将两棵树合并为一棵
parent[rootP] = rootQ;
// parent[rootQ] = rootP 也可以
count--;
```
我们一开始就是简单粗暴的把 `p` 所在的树接到 `q` 所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:
[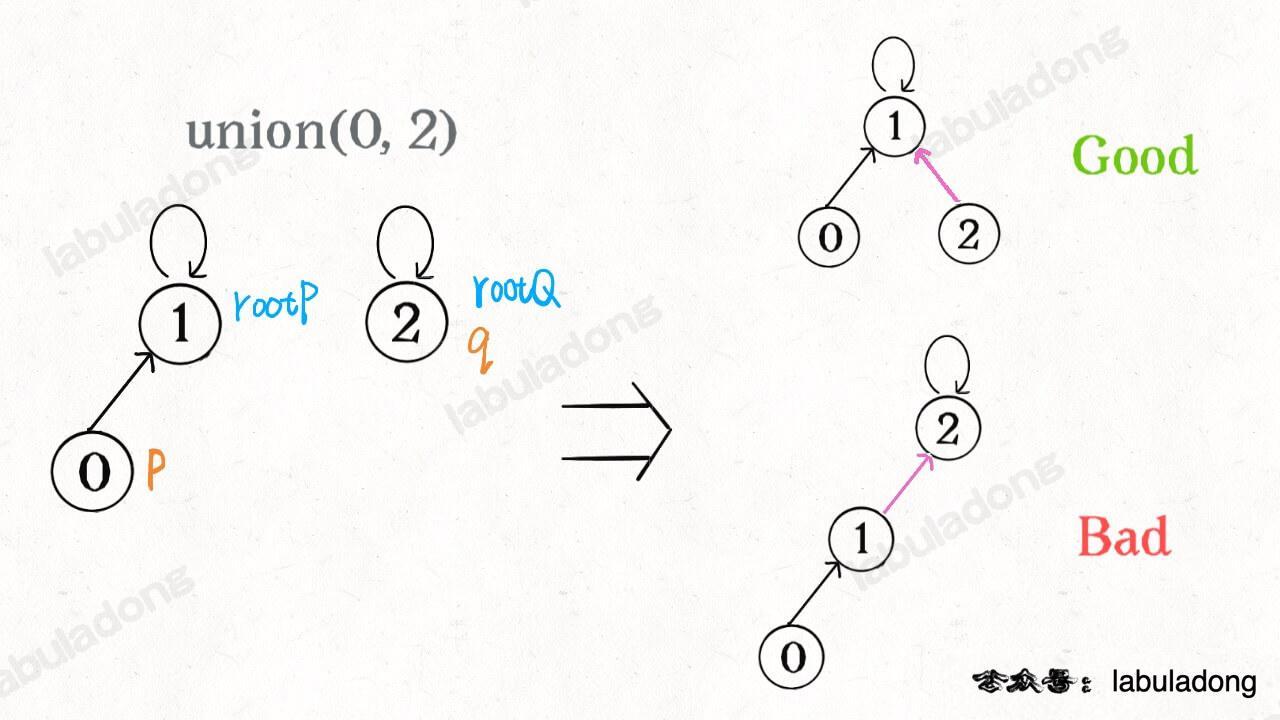](https://labuladong.github.io/algo/images/unionfind/7.jpg)
长此以往,树可能生长得很不平衡。**我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些**。解决方法是额外使用一个 `size` 数组,记录每棵树包含的节点数,我们不妨称为「重量」:
```java
class UF {
private int count;
private int[] parent;
// 新增一个数组记录树的“重量”
private int[] size;
public UF(int n) {
this.count = n;
parent = new int[n];
// 最初每棵树只有一个节点
// 重量应该初始化 1
size = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
size[i] = 1;
}
}
/* 其他函数 */
}
```
比如说 `size[3] = 5` 表示,以节点 `3` 为根的那棵树,总共有 `5` 个节点。这样我们可以修改一下 `union` 方法:
```java
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (size[rootP] > size[rootQ]) {
parent[rootQ] = rootP;
size[rootP] += size[rootQ];
} else {
parent[rootP] = rootQ;
size[rootQ] += size[rootP];
}
count--;
}
```
这样,通过比较树的重量,就可以保证树的生长相对平衡,树的高度大致在 `logN` 这个数量级,极大提升执行效率。
此时,`find` , `union` , `connected` 的时间复杂度都下降为 O(logN),即便数据规模上亿,所需时间也非常少。
#### 四、路径压缩
这步优化特别简单,所以非常巧妙。我们能不能进一步压缩每棵树的高度,使树高始终保持为常数?
[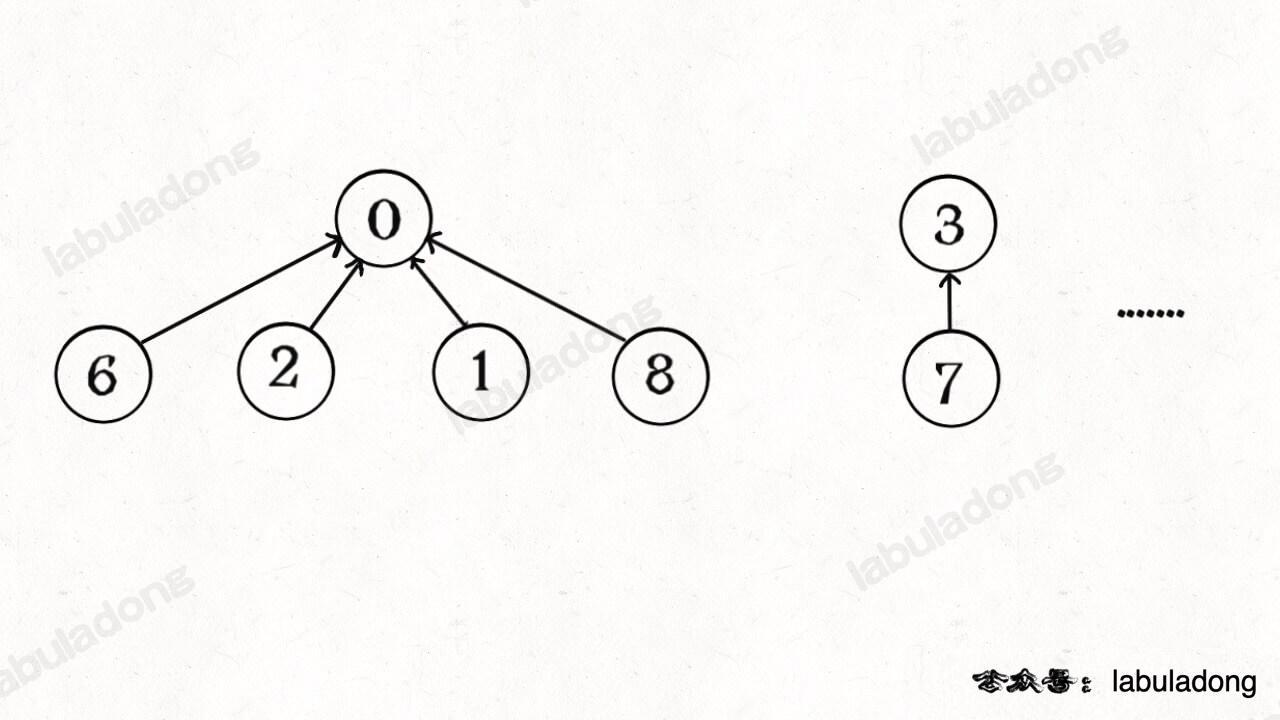](https://labuladong.github.io/algo/images/unionfind/8.jpg)
这样 `find` 就能以 O(1) 的时间找到某一节点的根节点,相应的,`connected` 和 `union` 复杂度都下降为 O(1)。
要做到这一点,非常简单,只需要在 `find` 中加一行代码:
```java
private int find(int x) {
while (parent[x] != x) {
// 进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
```
这个操作有点匪夷所思,看个 GIF 就明白它的作用了(为清晰起见,这棵树比较极端):
[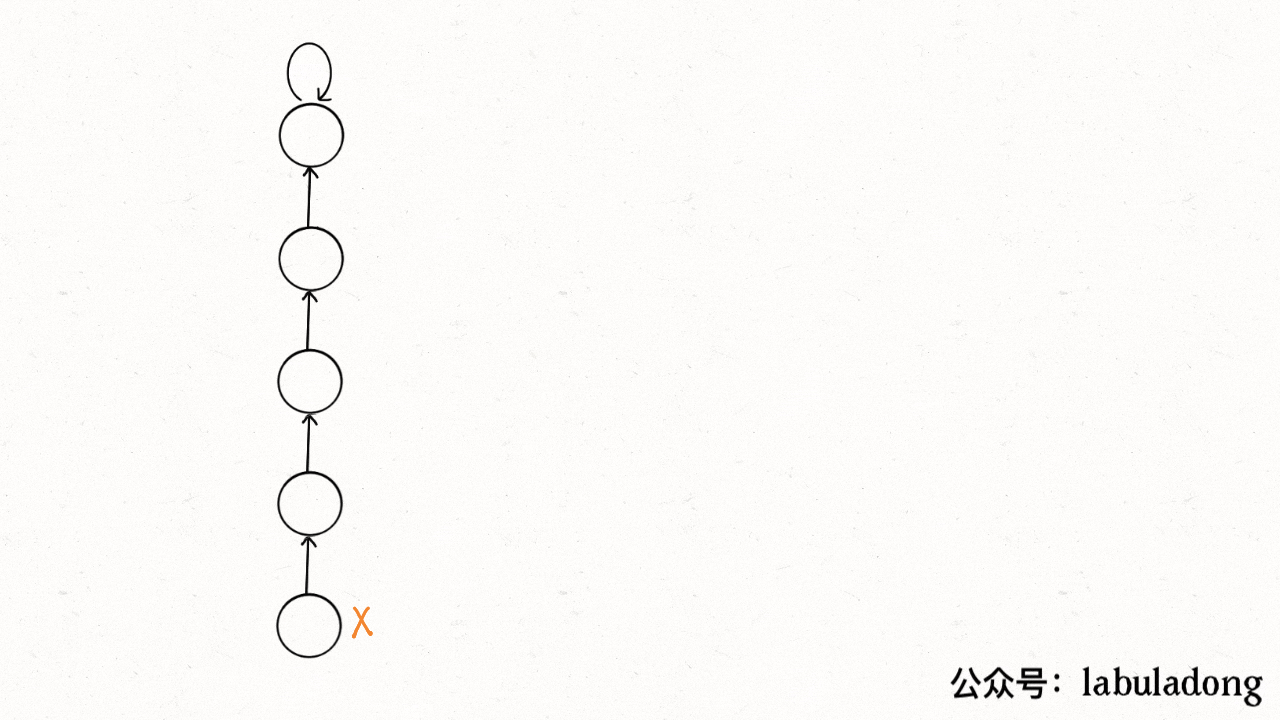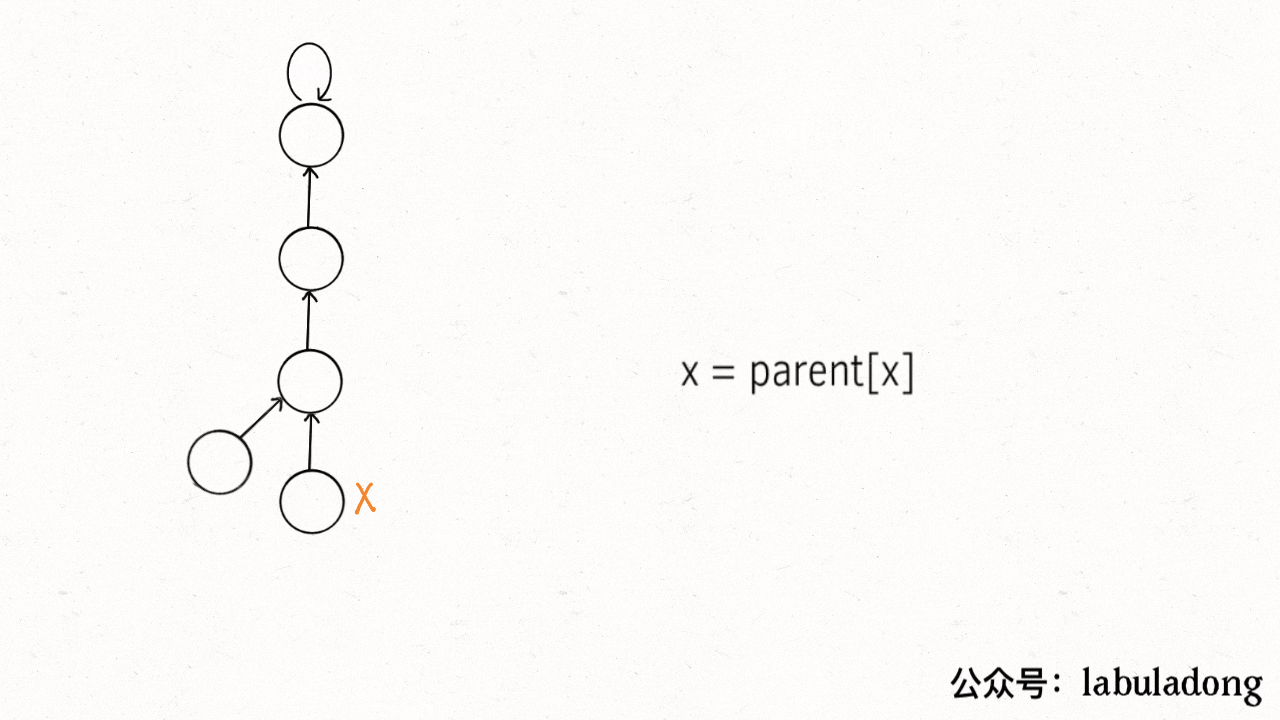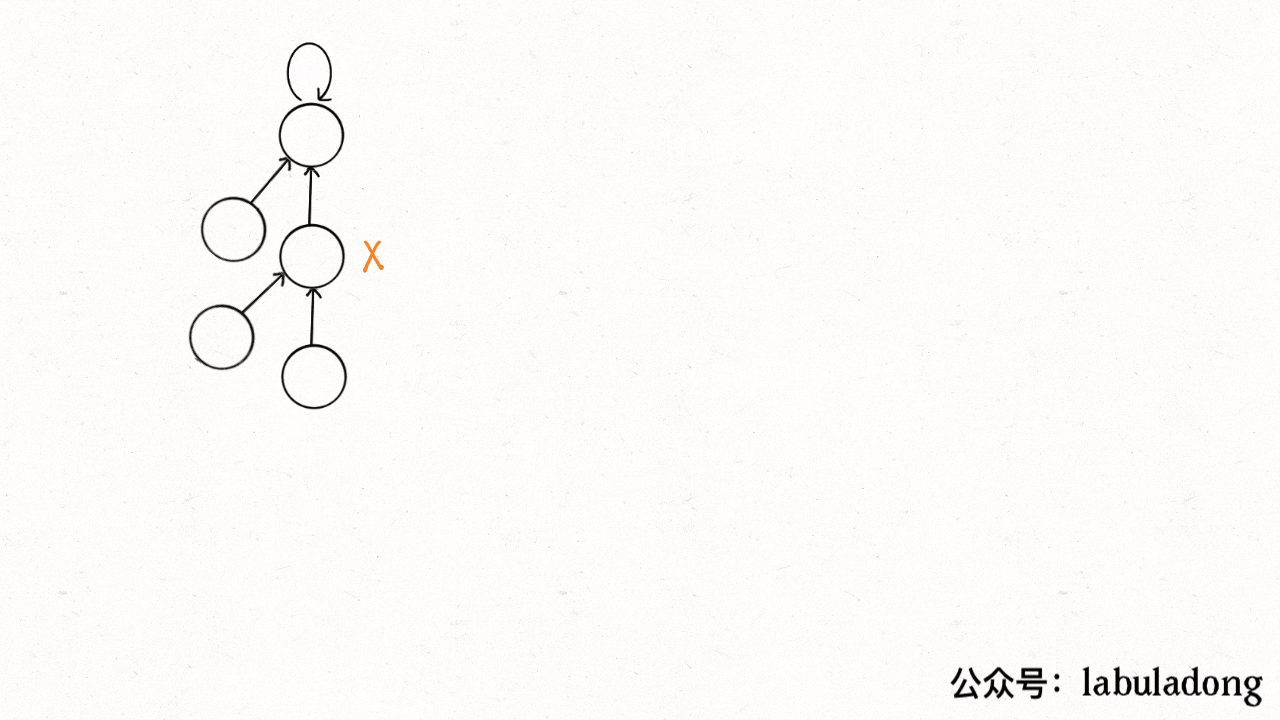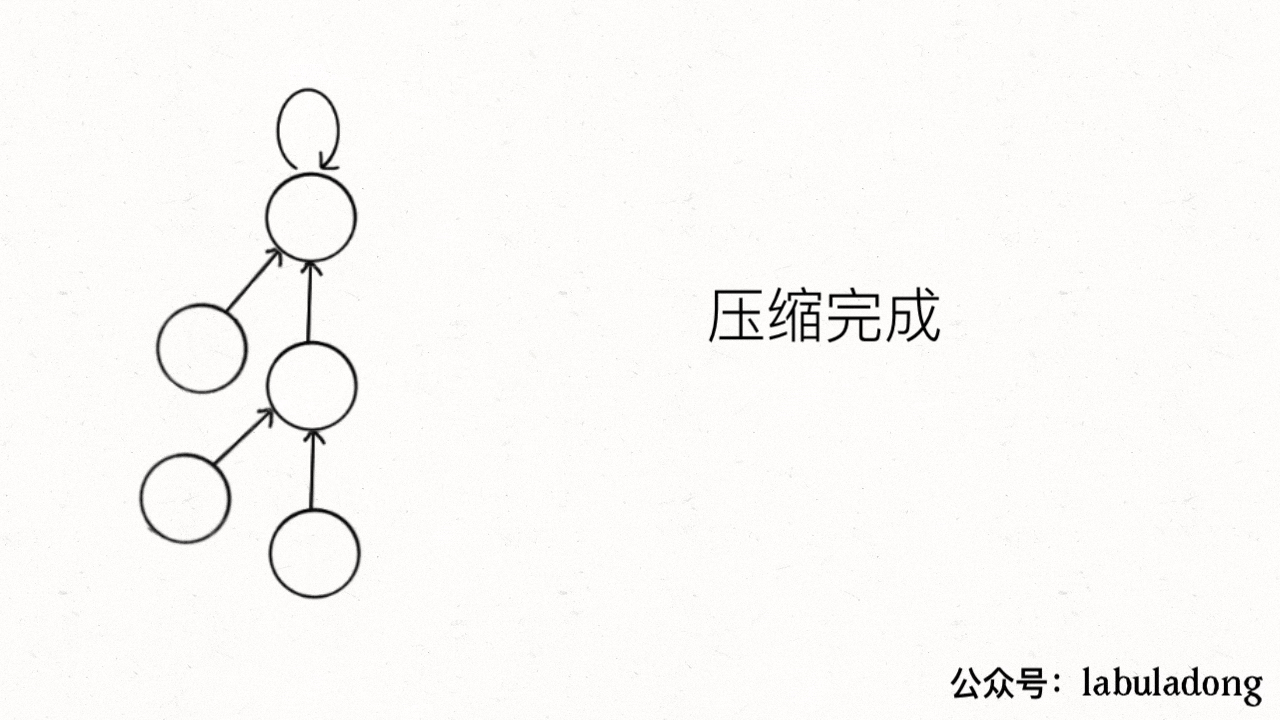](https://labuladong.github.io/algo/images/unionfind/9.gif)
1. p\[1]=2. p\[2]=3, p\[3]=4, p\[4]=5, p\[5]=5
2. x=1: p\[1] = p\[p\[2]]=3, x ->3; p\[3] = p\[p\[4]]=5
3. p\[1] = 3. p\[2]=3, p\[3]=5, p\[4]=5, p\[5]=5;
可见,调用 `find` 函数每次向树根遍历的同时,顺手将树高缩短了,最终所有树高都不会超过 3(`union` 的时候树高可能达到 3)。
> PS:读者可能会问,这个 GIF 图的find过程完成之后,树高恰好等于 3 了,但是如果更高的树,压缩后高度依然会大于 3 呀?不能这么想。这个 GIF 的情景是我编出来方便大家理解路径压缩的,但是实际中,每次find都会进行路径压缩,所以树本来就不可能增长到这么高,你的这种担心应该是多余的。
在这种情况下的完整代码:
```java
class UF {
// 连通分量个数
private int count;
// 存储一棵树
private int[] parent;
// 记录树的「重量」
private int[] size;
// n 为图中节点的个数
public UF(int n) {
this.count = n;
parent = new int[n];
size = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
size[i] = 1;
}
}
// 将节点 p 和节点 q 连通
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (size[rootP] > size[rootQ]) {
parent[rootQ] = rootP;
size[rootP] += size[rootQ];
} else {
parent[rootP] = rootQ;
size[rootQ] += size[rootP];
}
// 两个连通分量合并成一个连通分量
count--;
}
// 判断节点 p 和节点 q 是否连通
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
// 返回节点 x 的连通分量根节点
private int find(int x) {
while (parent[x] != x) {
// 进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
// 返回图中的连通分量个数
public int count() {
return count;
}
}
```
**路径压缩的第二种写法**是这样:
```java
// 第二种路径压缩的 find 方法
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
```
我一度认为这种递归写法和第一种迭代写法做的事情一样,但实际上是我大意了,有读者指出这种写法进行路径压缩的效率是高于上一种解法的。
这个递归过程有点不好理解,你可以自己手画一下递归过程。我把这个函数做的事情翻译成迭代形式,方面你理解它进行路径压缩的原理:
```java
// 这段迭代代码方便你理解递归代码所做的事情
public int find(int x) {
// 先找到根节点
int root = x;
while (parent[root] != root) {
root = parent[root];
}
// 然后把 x 到根节点之间的所有节点直接接到根节点下面
int old_parent = parent[x];
while (x != root) {
parent[x] = root;
x = old_parent;
old_parent = parent[old_parent];
}
return root;
}
```
这种路径压缩的效果如下:
[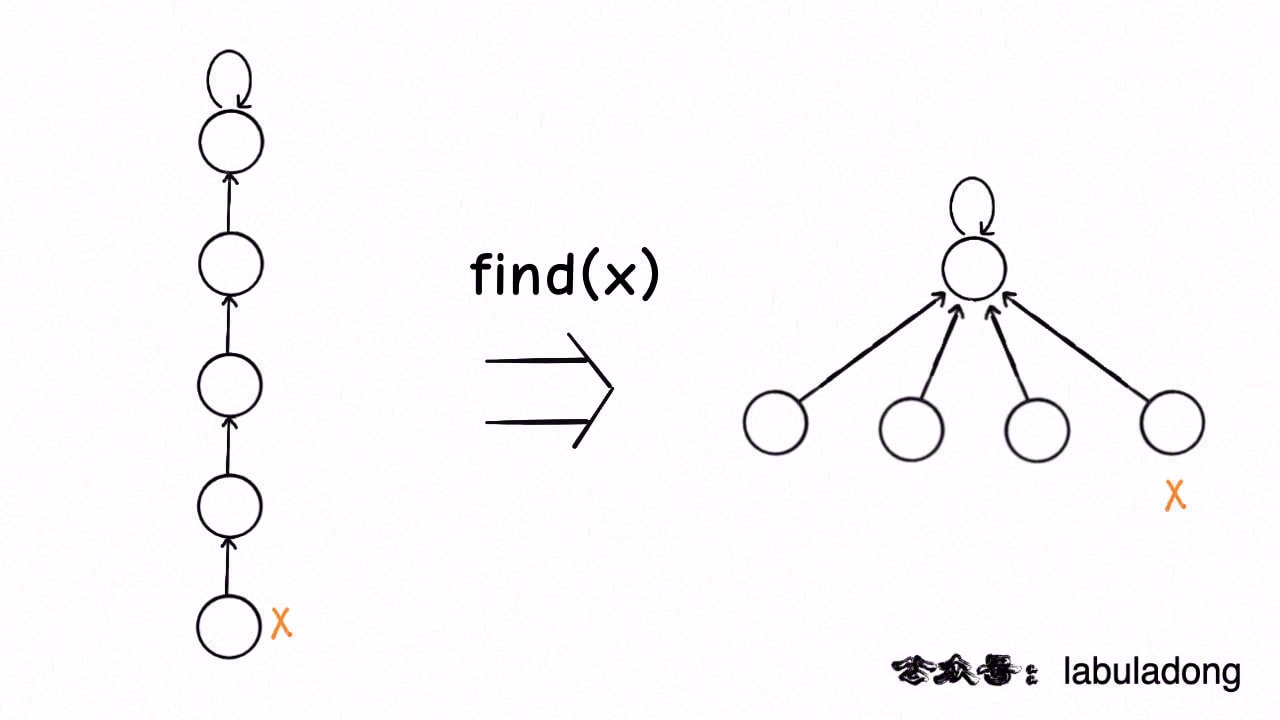](https://labuladong.github.io/algo/images/unionfind/10.jpeg)
比起第一种路径压缩,显然这种方法压缩得更彻底,直接把一整条树枝压平,一点意外都没有,所以从效率的角度来说,推荐你使用这种路径压缩算法。
**另外,如果路径压缩技巧将树高保持为常数了,那么 `size` 数组的平衡优化就不是特别必要了**。
所以你一般看到的 Union Find 算法应该是如下实现:
```java
class UF {
// 连通分量个数
private int count;
// 存储每个节点的父节点
private int[] parent;
// n 为图中节点的个数
public UF(int n) {
this.count = n;
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
// 将节点 p 和节点 q 连通
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
parent[rootQ] = rootP;
// 两个连通分量合并成一个连通分量
count--;
}
// 判断节点 p 和节点 q 是否连通
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// 返回图中的连通分量个数
public int count() {
return count;
}
}
```
#### 五、最后总结
Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点 `union`、判断两个节点的连通性 `connected`、计算连通分量 `count` 所需的时间复杂度均为 O(1)。
到这里,相信你已经掌握了 Union-Find 算法的核心逻辑,总结一下我们优化算法的过程:
1、用 `parent` 数组记录每个节点的父节点,相当于指向父节点的指针,所以 `parent` 数组内实际存储着一个森林(若干棵多叉树)。
2、用 `size` 数组记录着每棵树的重量,目的是让 `union` 后树依然拥有平衡性,保证各个 API 时间复杂度为 O(logN),而不会退化成链表影响操作效率。
3、在 `find` 函数中进行路径压缩,保证任意树的高度保持在常数,使得各个 API 时间复杂度为 O(1)。使用了路径压缩之后,可以不使用 `size` 数组的平衡优化。
* [Union-Find算法应用](https://labuladong.github.io/algo/2/19/38/) (leetcode 130, 990)
#### 三、简单总结
使用 Union-Find 算法,主要是**如何把原问题转化成图的动态连通性问题**。对于算式合法性问题,可以直接利用等价关系,对于棋盘包围问题,则是利用一个虚拟节点,营造出动态连通特性。
另外,将二维数组映射到一维数组,利用方向数组 `d` 来简化代码量,都是在写算法时常用的一些小技巧,如果没见过可以注意一下。
很多**更复杂的 DFS 算法问题,都可以利用 Union-Find 算法更漂亮的解决**。LeetCode 上 Union-Find 相关的问题也就二十多道,有兴趣的读者可以去做一做。
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://junnie.gitbook.io/nine-chapter/10.-graph/introduction/union-find.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.