> For the complete documentation index, see [llms.txt](https://junnie.gitbook.io/nine-chapter/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://junnie.gitbook.io/nine-chapter/2.binary-tree/230.-kth-smallest-element-in-a-bst-m.md).
# 230. Kth Smallest Element in a BST (M)
Given the `root` of a binary search tree, and an integer `k`, return *the* `kth` *smallest value (**1-indexed**) of all the values of the nodes in the tree*.
**Example 1:**
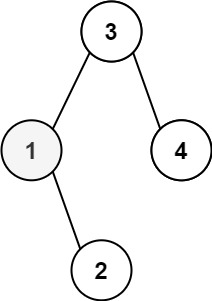
```
Input: root = [3,1,4,null,2], k = 1
Output: 1
```
**Example 2:**
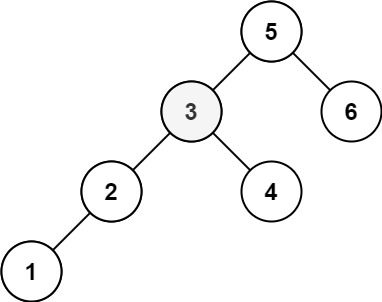
```
Input: root = [5,3,6,2,4,null,null,1], k = 3
Output: 3
```
**Constraints:**
* The number of nodes in the tree is `n`.
* `1 <= k <= n <= 104`
* `0 <= Node.val <= 104`
**Follow up:** If the BST is modified often (i.e., we can do insert and delete operations) and you need to find the kth smallest frequently, how would you optimize?
### Solution 1: (Standard inorder traverse)
一个直接的思路就是升序排序,然后找第 `k` 个元素呗。BST 的中序遍历其实就是升序排序的结果,找第 `k` 个元素肯定不是什么难事。
时间复杂度O(n) 空间复杂度O(n)
按照这个思路,可以直接写出代码:
```java
int kthSmallest(TreeNode root, int k) {
// 利用 BST 的中序遍历特性
traverse(root, k);
return res;
}
// 记录结果
int res = 0;
// 记录当前元素的排名
int rank = 0;
void traverse(TreeNode root, int k) {
if (root == null) {
return;
}
traverse(root.left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
// 找到第 k 小的元素
res = root.val;
return;
}
/*****************/
traverse(root.right, k);
}
```
### Solution 2: (Non recursive inorder traverse)
详情见LeetCode 67, 区别就是判断标准不是while(!stack.empty()) 而是只走k-1步,stack.peek() 就是第k小得元素。
```
public int kthSmallest(TreeNode root, int k) {
List list = new ArrayList();
Stack stack = new Stack();
while(root != null)
{
stack.push(root);
root = root.left;
}
for(int i = 1; i< k; i++)
{
TreeNode top = stack.pop();
list.add(top.val);
if(top.right != null)
{
TreeNode rightNode = top.right;
while(rightNode !=null)
{
stack.push(rightNode);
rightNode = rightNode.left;
}
}
}
return stack.peek().val;
}
```
### Solution 3:
我们旧文 [高效计算数据流的中位数](https://labuladong.github.io/algo/2/20/46/) 中就提过今天的这个问题:
> 如果让你实现一个在二叉搜索树中通过排名计算对应元素的方法 `select(int k)`,你会怎么设计?
如果按照我们刚才说的方法,利用「BST 中序遍历就是升序排序结果」这个性质,每次寻找第 `k` 小的元素都要中序遍历一次,最坏的时间复杂度是 `O(N)`,`N` 是 BST 的节点个数。
要知道 BST 性质是非常牛逼的,像红黑树这种改良的自平衡 BST,增删查改都是 `O(logN)` 的复杂度,让你算一个第 `k` 小元素,时间复杂度竟然要 `O(N)`,有点低效了。
所以说,计算第 `k` 小元素,最好的算法肯定也是对数级别的复杂度,不过这个依赖于 BST 节点记录的信息有多少。
我们想一下 BST 的操作为什么这么高效?就拿搜索某一个元素来说,BST 能够在对数时间找到该元素的根本原因还是在 BST 的定义里,左子树小右子树大嘛,所以每个节点都可以通过对比自身的值判断去左子树还是右子树搜索目标值,从而避免了全树遍历,达到对数级复杂度。
那么回到这个问题,想找到第 `k` 小的元素,或者说找到排名为 `k` 的元素,如果想达到对数级复杂度,关键也在于每个节点得知道他自己排第几。
比如说你让我查找排名为 `k` 的元素,当前节点知道自己排名第 `m`,那么我可以比较 `m` 和 `k` 的大小:
1、如果 `m == k`,显然就是找到了第 `k` 个元素,返回当前节点就行了。
2、如果 `k < m`,那说明排名第 `k` 的元素在左子树,所以可以去左子树搜索第 `k` 个元素。
3、如果 `k > m`,那说明排名第 `k` 的元素在右子树,所以可以去右子树搜索第 `k - m - 1` 个元素。
这样就可以将时间复杂度降到 `O(logN)` 了。
那么,如何让每一个节点知道自己的排名呢?
这就是我们之前说的,需要在二叉树节点中维护额外信息。**每个节点需要记录,以自己为根的这棵二叉树有多少个节点**。
也就是说,我们 `TreeNode` 中的字段应该如下:
```java
class TreeNode {
int val;
// 以该节点为根的树的节点总数
int size;
TreeNode left;
TreeNode right;
}
```
有了 `size` 字段,外加 BST 节点左小右大的性质,对于每个节点 `node` 就可以通过 `node.left` 推导出 `node` 的排名,从而做到我们刚才说到的对数级算法。
当然,`size` 字段需要在增删元素的时候需要被正确维护,力扣提供的 `TreeNode` 是没有 `size` 这个字段的,所以我们这道题就只能利用 BST 中序遍历的特性实现了,但是我们上面说到的优化思路是 BST 的常见操作,还是有必要理解的。
具体解法可以通过一个HashMap 来实现上述每个节点对size 的属性。
时间复杂度 O(n)O(n) 最好最坏都是。 算法思想类似于 Quick Select。 这个算法的好处是,如果多次查询的话,给每个节点统计儿子个数这个过程只需要做一次。查询可以很快。
```
/**
* Definition of TreeNode:
* public class TreeNode {
* public int val;
* public TreeNode left, right;
* public TreeNode(int val) {
* this.val = val;
* this.left = this.right = null;
* }
* }
*/
public class Solution {
/**
* @param root: the given BST
* @param k: the given k
* @return: the kth smallest element in BST
*/
public int kthSmallest(TreeNode root, int k) {
Map numOfChildren = new HashMap<>();
countNodes(root, numOfChildren);
return quickSelectOnTree(root, k, numOfChildren);
}
private int countNodes(TreeNode root, Map numOfChildren) {
if (root == null) {
return 0;
}
int left = countNodes(root.left, numOfChildren);
int right = countNodes(root.right, numOfChildren);
numOfChildren.put(root, left + right + 1);
return left + right + 1;
}
private int quickSelectOnTree(TreeNode root, int k, Map numOfChildren) {
if (root == null) {
return -1;
}
int left = root.left == null ? 0 : numOfChildren.get(root.left);
if (left >= k) {
return quickSelectOnTree(root.left, k, numOfChildren);
}
if (left + 1 == k) {
return root.val;
}
return quickSelectOnTree(root.right, k - left - 1, numOfChildren);
}
}
```
Submitted from LeetCode:
```
class Solution {
Map map = new HashMap();
int result = 0;
public int kthSmallest(TreeNode root, int k)
{
//maintain a mapping have every node location info
countChildNode(root);
helper(root, k);
return result;
}
public int countChildNode(TreeNode root)
{
if(root == null)
{
return 0;
}
int left = countChildNode(root.left);
int right = countChildNode(root.right);
map.put(root, left+right+1);
return left+right+1;
}
public void helper (TreeNode root, int k)
{
if(root == null)
{
return;
}
// 对于每个节点 node 就可以通过 node.left 推导出 node 的排名
int current;
if(root.left == null)
{
//root.left == null 说明当前root就是最左边的,就是第一。
current = 1;
}else
{
current = map.get(root.left)+1;
}
if(k == current)
{
result = root.val;
return;
}
// k is in the right tree of the current
if(k > current)
{
helper(root.right, k-current);
}
// k is in the left tree of the current
if(k < current)
{
helper(root.left, k);
}
}
}
```