双向 BFS 优化
https://labuladong.gitee.io/algo/1/5/
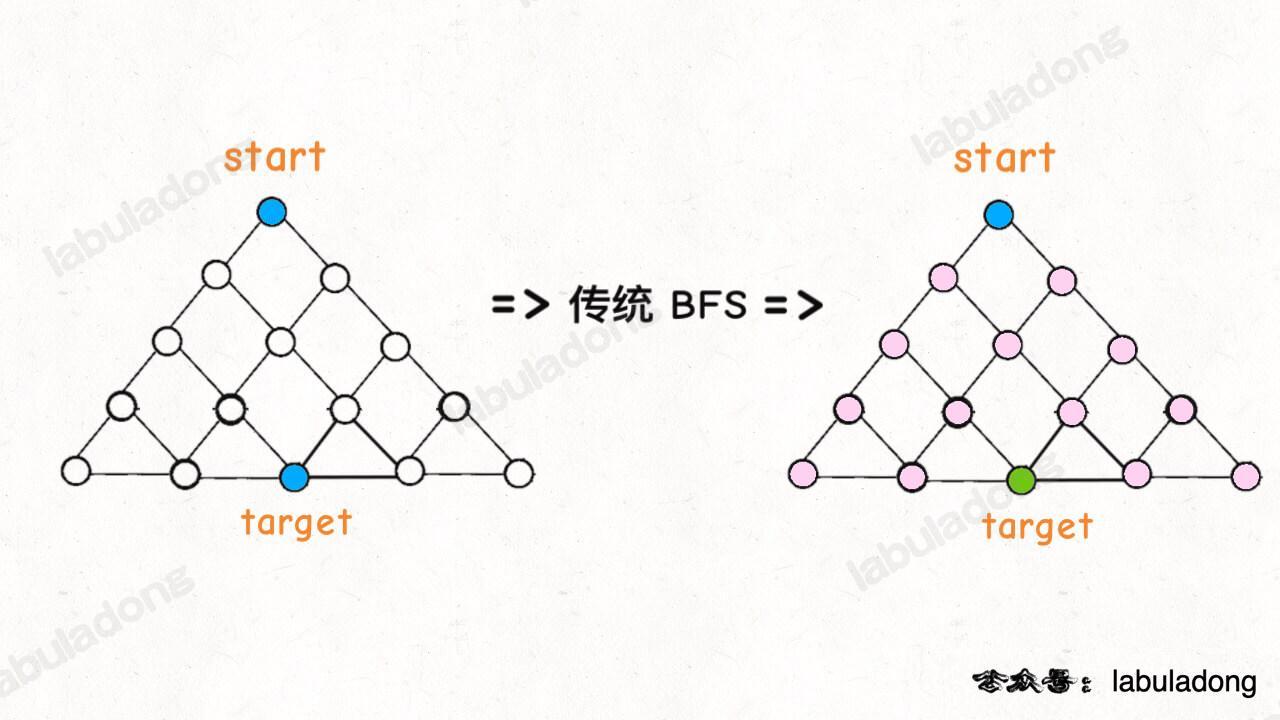
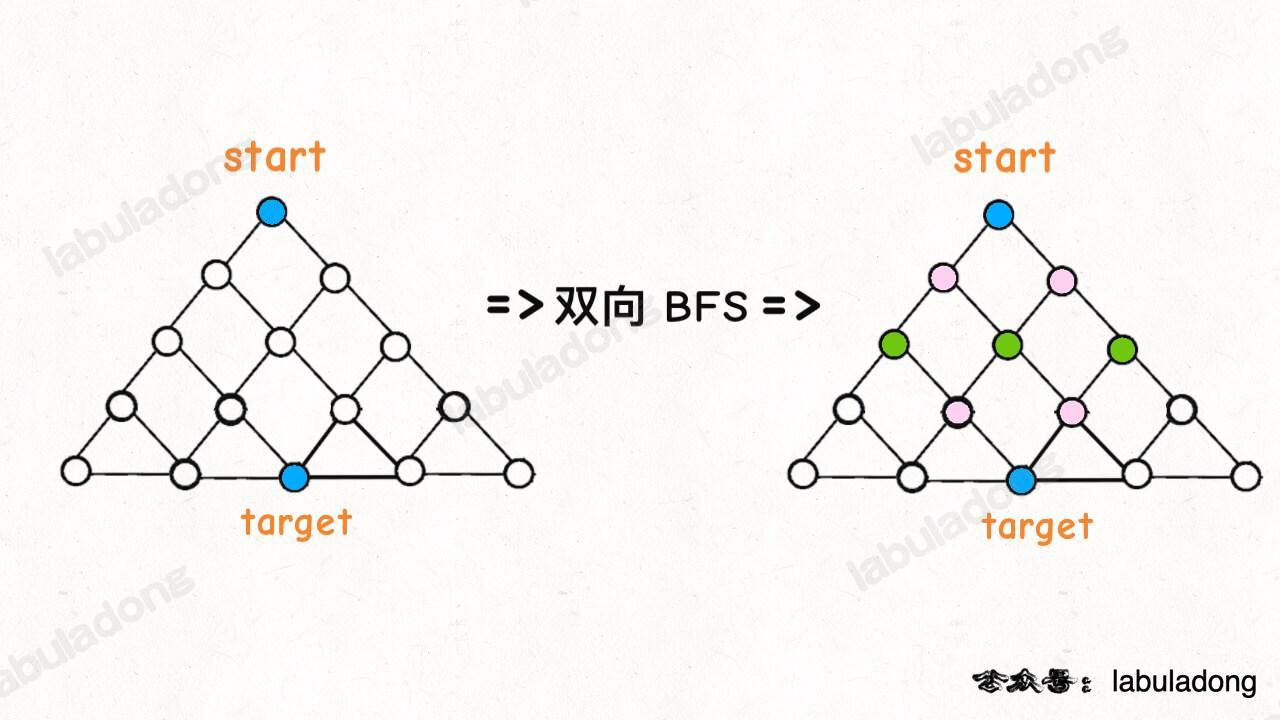
int openLock(String[] deadends, String target) {
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
// 用集合不用队列,可以快速判断元素是否存在
Set<String> q1 = new HashSet<>();
Set<String> q2 = new HashSet<>();
Set<String> visited = new HashSet<>();
int step = 0;
q1.add("0000");
q2.add(target);
while (!q1.isEmpty() && !q2.isEmpty()) {
// 哈希集合在遍历的过程中不能修改,用 temp 存储扩散结果
Set<String> temp = new HashSet<>();
/* 将 q1 中的所有节点向周围扩散 */
for (String cur : q1) {
/* 判断是否到达终点 */
if (deads.contains(cur))
continue;
if (q2.contains(cur))
return step;
visited.add(cur);
/* 将一个节点的未遍历相邻节点加入集合 */
for (int j = 0; j < 4; j++) {
String up = plusOne(cur, j);
if (!visited.contains(up))
temp.add(up);
String down = minusOne(cur, j);
if (!visited.contains(down))
temp.add(down);
}
}
/* 在这里增加步数 */
step++;
// temp 相当于 q1
// 这里交换 q1 q2,下一轮 while 就是扩散 q2
q1 = q2;
q2 = temp;
}
return -1;
}Last updated